如何评估数据适不适合放入Redis中?
发布: 来源: PHP粉丝网 添加日期:2022-08-07 18:09:49 浏览: 评论:0
当项目中引入了 Redis 做分布式缓存,那么就会面临这样的问题:
哪些数据应该放到缓存中?依据是什么?
缓存数据是采用主动刷新还是过期自动失效?
如果采用过期自动失效,那么失效时间如何制定?
正好这两周我们项目做了相关的评估,把过程记录下来和大家分享分享;当然过程中用到了很多“笨办法”,如果你有更好的办法,也希望能分享给我。
01. 项目背景
我们的项目是一个纯服务平台,也就是只提供接口服务,并没有操作页面的,项目的接口日调用量大约在 200 万次,高峰期也就 1000 万出头,因为大部分接口是面向内部系统的,所以大部分请求集中在工作日的 9 点到 21 点,高峰期的时候系统的 QPS 在 300-400 之间。
因为我们项目数据存储使用的是 MongoDB,理论上支撑这个量级的 QPS 应该是绰绰有余,但是我有这么几点观察和考虑:
MongoDB 中虽然是整合好的数据,但是很多场景也不是单条查询,夸张的时候一个接口可能会返回上百条数据,回参报文就有两万多行(不要问我能不能分页返回......明确告诉你不能);
MongoDB 中虽然是整合好的数据,但是很多场景也不是单条查询,夸张的时候一个接口可能会返回上百条数据,回参报文就有两万多行(不要问我能不能分页返回......明确告诉你不能);
目前项目 99.95% 的接口响应时间都在几十到几百毫秒,基本可以满足业务的需要,但是还是有 0.05% 的请求会超过 1s 响应,偶尔甚至会达到 5s、10s;
观察这些响应时间长的请求,大部分时间消耗在查询 MongoDB 上,但是当我将请求报文取出,再次手动调用接口的时候,依然是毫秒级返回;MongoDB 的配置一般,时刻都有数据更新,而且我观察过,响应时间长的这些接口,那个时间点请求量特别大;
MongoDB 查询偶尔会慢的原因我我还在确认,我现在能想到的原因比如:大量写操作影响读操作、锁表、内存小于索引大小等等,暂时就认为是当时那一刻 MongoDB 有压力;我观察过,响应时间长的这些接口,那个时间点请求量特别大,这一点就不在这里具体分析了。
虽然一万次的请求只有四五次响应时间异常,但是随着项目接入的请求越来越大,保不齐以后量变产生质变,所以还是尽量将危机扼杀在摇篮里,所以果断上了 Redis 做分布式缓存。
02. 接口梳理
下一步就是对生产环境现有接口进行统计和梳理,确定哪些接口是可以放到缓存中的,所以首先要对每一个接口的调用量有大概的统计,因为没有接入日志平台,所以我采用了最笨的办法,一个一个接口的数嘛。
把工作日某一天全天的日志拉下来,我们四台应用服务器,每天的日志大概 1 个G,还好还好;
通过 EditPlus 这个工具的【在文件中查找】的功能,查询每个接口当天的调用量,已上线 30 个接口,有几分钟就统计出来了,反正是一次性的工作,索性就手动统计了;
一天也调不了几次的接口,就直接忽略掉了,我基本上只把日调用量上万的接口都留下来,进行下一步的分析。
03. 字典表、配置类的数据
这一类的数据是最适合放在缓存中的,因为更新频率特别低,甚至有时候 insert 了之后就再也不做 update ,如果这类数据的调用量比较大,是一定要放到 Redis 中的;
至于缓存策略,可以在更新的时候双写数据库和 Redis,也可以采用自动失效的方式,当然这个失效时间可以放得比较长一些;针对我们项目,我采用的是半夜 12 点统一失效的策略,第一因为我们系统这类数据,是夜间通过 ETL 抽取过来的,每天同步一次,第二就是我们不怕缓存雪崩,没有那么大的访问量,夜间更没有什么访问量了。
04. 明显是热点数据的数据
有一类数据,很明显就是热点数据;
我们就有一个接口,虽然是业务数据,不过数据总量只有几千条,但是每天的调用量大约在 40 万,而且更新频率不是很高,这类数据放入 Redis 中也就再适合不过了;至于缓存策略么,因为数据也是从其他系统同步过来的,根据数据同步的时间,我们最终采用一个小时的失效时间。
05. 其余数据的评估
其实前两种数据很容易就能评估出来,关键是这类数据的评估:
我们有一个接口日调用量 20-30 万,量不大,但是查询和处理逻辑比较复杂;
基础数据量太大,无法把所有数据都放入 Redis 中;
无法把基础数据直接放入 Redis 中,因为有多重查询维度(条件);
无法确定每条数据的调用频率是怎么样的,最悲观的结果,每条数据当天只调用一次,这样就没有缓存的必要了。
但是咱也不能一拍脑袋就说:“调用量挺大的,直接放到 Redis 中吧”,或者“不好评估,算了吧,别放缓存了”,做任何一个决定还是需要有依据的,于是我是这样做的:
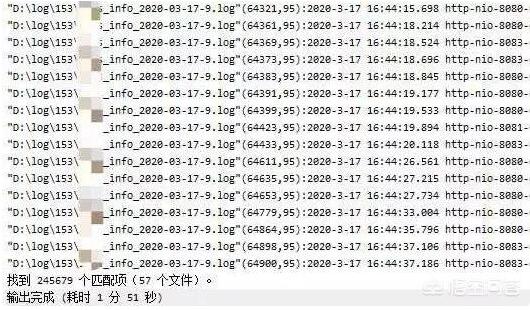
Step 1. 把该接口当天的所有日志都找出来
几十个日志文件肯定不能一个一个翻,要么就自己写个程序把需要的数据扒出来,但是考虑到这个工作可能只做一次,我还是尽量节省一些时间吧。
依然使用 EditPlus 这个工具的【在文件中查找】的功能,在查询结果框中【复制所有内容】,花了两分钟,就把 24 万条日志找出来了。
Step 2. 把数据导入到数据库中进行下一步分析
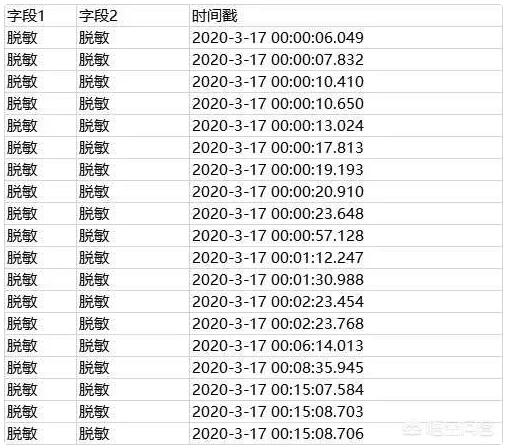
每一条日志大概是这样的:
XXXX.log"(64190,95):2020-3-17 16:44:10.092 http-nio-8080-exec-5 INFO 包名.类名 : 请求参数:args1={"字段1":"XXX","字段2":"YYY"}
日志里面我只需要三个内容:请求报文中的字段 1 和字段 2,以及调用时间;怎么摘出来?写个程序?当然没问题,但是我懒呀,几分钟能做好的事情为什么话花几十分钟呢?而且这工作是一次性的,于是:
全文替换:[ 2020-3-17 ] 替换成 [ /t2020-3-17 ] ,也就是在时间戳前面加一个 tab;
全文替换:[ {"字段1":" ] 替换成 [ /t ] ;
全文替换:[ ","字段2":" ] 替换成 [ /t ] ;
全文替换:[ "} ] 替换成 [ ],也就是替换成空 ;
全选复制,粘贴到 excel 中,excel 自动按照 tab 换列;
删除不需要的列,只留字段 1 和字段 2 的内容,以及时间戳;
这几步操作用不了一分钟。
Step 3. 调用频率分析
当把数据进入到数据库中,就根据我们的需要进行分析了;我们主要想知道,相同的入参会不会重复调用?每次调用间隔的时间是多少?一个 SQL 搞定:
当然调用间隔时间的统计,这里统计的不精确,具体我不解释了,你们细品...
总之吧,全天 24 万的调用量,其中 10 万只调用了一次,14 万的数据会在短时间内重复调用,有一些数据甚至会在几分钟之内重复查询几十次,所以这个接口还是比较适合放入到 Redis 中的。
Step 4. 数据怎么存?
再说说我们的数据用什么格式保存到 Redis 中,一图胜千言:
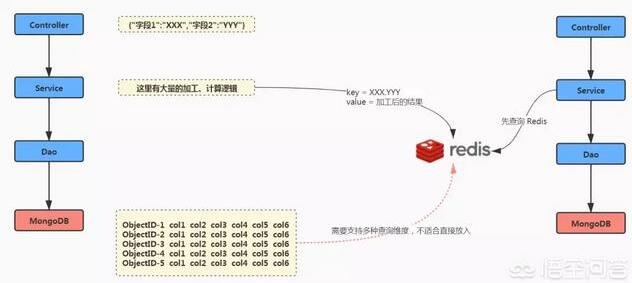
至于缓存更新策略嘛,我们依然使用设置失效时间的方式,根据数据同步的时间和调用统计结果,这个时间设置成 15 分钟比较合适。
可以看到在这个评估过程中,我所有操作都保持了“能偷懒就偷懒”这个好习惯,保持高效,善用工具,节约不必要的时间,全部过程花了两个小时,其中大部分时间是在数据导入,几乎用了一个半小时,还好在这个过程中我还能做其他的工作。
网友二:
如何评估数据适不适合放入Redis中?这个好像都不怎么用评估,在互联网公司待了好几年,行不行放进去试试就行,工作这几年时间,还没有见过不能放入Redis的数据场景。下面就以个人的经历,简单分享一些特殊的数据场景和使用过程中的问题,娱乐为主,甄别借鉴。
在负责前台业务时,配置数据是一种很典型的数据场景,如 APP 首页所加载的轮播图、ICON跳转信息等,这些数据属于典型的低频变更、高频访问型数据,面向所有用户请求响应,产品运营在配置后台变更。我负责的业务本身访问量也不高,PV 110w,UV 80,峰值QPS 200+,处理方案是被动配置信息缓存,缓存时间为 5 min,产品运营配置的数据最悲观的情况下 5 min生效,产品侧接受,研发侧实现简单。但在维护过程中,发现 redis 的 key 生成规则中有当前时间因子,导致该配置信息缓存永远都取不到,这种低级错误读者感觉别出心裁,也很不容易定位。幸好我们的业务并发并不高,要不然数据库压力就够呛了。
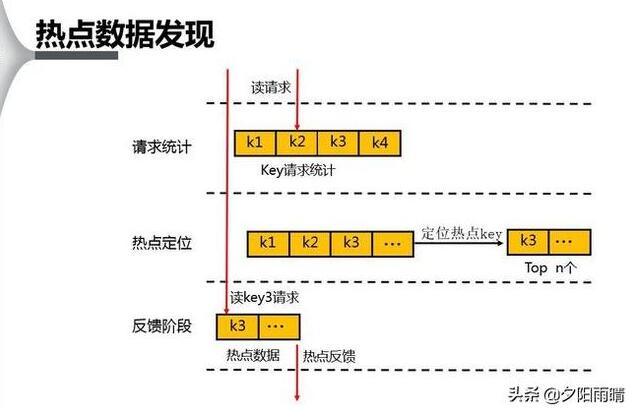
在维护页面型业务时,发现该业务的整个页面进行了缓存,定时调度每分钟拉群上游数据,结合本地 vm 模板进行渲染,然后将选择结果放入 redis,当有用户请求时,直接返回该渲染完成的页面html,起到快速响应的目的。这种快速响应用户请求优化的方式,第一次见到,很有借鉴意义,页面的响应优化方面可以考虑的层面又多了一些方式。
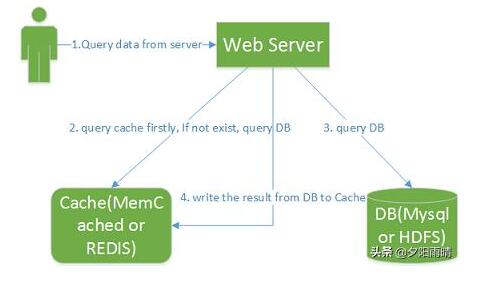
还有一种高性能的业务场景,业务 QPS 10w+,这种请求并发,关系型数据库往往无能为力,曾经历过以 redis 为中心,搭建整个应用体系,用户型数据永久存储,为保证数据的准备性,异步消息队列消费入库,数据库中数据主要用作维护和数据备份。所有的请求都由 redis 反馈结果,redis中无数据,就表明该用户数据不存在,这种架构可以轻松支撑起 10w+ 的QPS。但也不是没有问题的,运营的久了,往往会出现数据库和缓存的数据不一致的情况,这种时候就考虑结合数据库中数据,对缓存中数据进行清洗和补偿。
以上,仅是职业生涯遇到的一些特殊场景,处理方案或许不那么完美,但也足够支撑业务。在开发中,着力追求技术方案完美值得肯定,但也尽量避免过度设计。在当下这个迭代速度超快的业务和技术场景中,能够支撑业务发展就是一种好的架构设计。
网友三:
咱也不知道,咱也不敢说,觉得亚马逊说的比我好。本文来自亚马逊。

Redis 热门使用案例
1 - 缓存
Redis 是实施高可用性内存中缓存的极佳选择,它可以降低数据访问延迟、提高吞吐量,并可以减轻关系数据库和应用程序或 NoSQL 数据库和应用程序的负载。Redis 能够以亚毫秒级的响应时间为频繁请求的项目提供支持,并支持您轻松扩展以满足更高负载的需求,而无需增加昂贵的后端。使用 Redis 缓存的常见示例包括:数据库查询结果缓存、持久性会话缓存、网页缓存,以及缓存频繁使用的对象(例如映像、文件和元数据)等。
2 - 聊天、消息收发和队列
Redis 支持发布/订阅、模式匹配和各种数据结构,例如列表、排序集和哈希。这使得 Redis 能够支持高性能的聊天室、实时评论流、社交媒体信息以及服务器内部通信。借助 Redis 列表数据结构,客户能够轻松实施轻量级队列。这类列表提供了原子操作和屏蔽功能,适用于各种需要可靠消息代理或循环表的应用程序。
3 - 游戏排行榜
Redis 是寻求构建实时排行榜的游戏开发者的热门选择。可直接使用 Redis 有序集数据结构,此结构实现了元素的唯一性,同时又可维护按用户分数排序的列表。创建实时排序表像用户分数在每次更改后进行更新一样简单。您也可以使用时间戳作为分数,使用有序集处理时间序列数据。
4 - 会话存储
作为具备高可用性和持久性的内存中数据存储,Redis 是应用程序开发人员用来为 Internet 级应用程序存储和管理会话数据的常见选择。Redis 可提供管理会话数据(如用户配置文件、凭证、会话状态和用户特定的个性化)所需的亚毫秒级延迟、可扩展性和弹性。
5 - 富媒体流
Redis 提供了一个快速的内存中数据存储,支持实时流使用案例。Redis 可存储用于用户配置文件和查看历史记录的元数据、数百万用户的身份验证信息/令牌,以及清单文件,以便 CDN 能够将视频一次性流式传输到数百万移动和桌面用户。
6 - 地理空间
Redis 提供专门构建的内存中数据结构和运算符,以便从规模和速度方面管理实时地理空间数据。由于包含可用于实时存储、处理和分析地理空间数据的 GEOADD、GEODIST、GEORADIUS 和 GEORADIUSBYMEMBER 等多个命令,Redis 可以轻松快速地进行地理空间分析。您可以使用 Redis 向应用程序添加基于位置的功能,如驾驶时间、驾驶距离和兴趣点。
7 - Machine Learning
数据驱动的现代化应用程序需要机器学习来快速处理数据量、数据多样性和数据速率,并自动制定决策。对于游戏和金融服务中的欺诈检测、广告技术中的实时竞价,以及共享约会和共享单车中的配对等使用案例而言,能够在几十毫秒内处理实时数据并做出决策至关重要。Redis 为您提供了快速的内存中数据存储,可快速构建、培训和部署机器学习模型。
8 - 实时分析
Redis 可作为内存中数据存储,与流解决方案(例如 Apache Kafka 和 Amazon Kinesis)搭配使用,以亚毫秒级延迟提取、处理和分析实时数据。Redis 是实时分析使用案例的理想选择,例如社交媒体分析、广告投放、个性化和 IoT。
Redis 是什么?
Redis 指远程字典服务器 (Remote Dictionary Server),是一款快速的开源内存中键值数据存储,可用作数据库、缓存、消息代理和队列。Redis 创始开发人员 Salvatore Sanfilippo 为了提高他的意大利初创企业的可扩展性,启动了此项目。Redis 现可提供亚毫秒级的响应时间,每秒处理数百万个请求,支持游戏、广告技术、金融服务、医疗保健和物联网等领域的实时应用程序。Redis 是缓存、会话管理、游戏、排行榜、实时分析、地理空间、网约车、聊天/消息收发、媒体流和发布/订阅等应用领域的流行选择。
Redis 如何运作?
数据库将数据存储在磁盘或 SSD 上,而所有 Redis 数据驻留在内存中。由于无需访问磁盘,Redis 等内存数据存储避免了查找时间延迟,并且可以在几微秒内访问数据。Redis 提供多种数据结构、高可用性、地理空间、Lua 脚本、事务、磁盘持久性和群集支持,让实时互联网级应用程序的构建变得更加简单。
Redis 与 Memcached
Both Redis 和 MemCached 都属于开源内存中数据存储。Memcached 是一种高性能的分布式内存缓存服务,设计颇为简洁,而 Redis 具有丰富的功能,能够有效满足多种使用案例的要求。如需更详细比较两者的功能以帮助决策。 它们支持关系数据库或键值数据库以提高性能,例如 MySQL、Postgres、Aurora、Oracle、SQL Server、DynamoDB 等等。
Redis 的优势
1 - 内存中数据存储
PostgreSQL、Cassandra、MongoDB 等数据库将大部分数据存储在磁盘或 SSD 上,而 Redis 则将所有数据存储在服务器的主内存上。在传统的基于磁盘的数据库中,大多数操作都需要往返磁盘。相比之下,Redis 之类的内存数据存储不会受到相同的损失。因此,它们可以支持更多操作并缩短响应时间。它可以提供超快的性能,读取或写入操作的平均时间不到一毫秒,并支持每秒数百万次的操作。
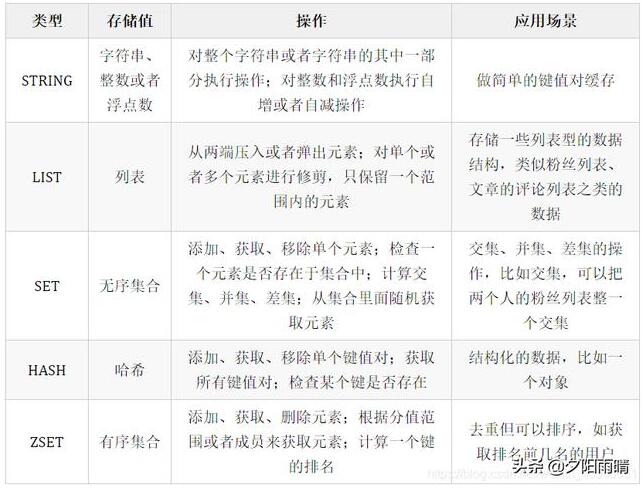
2 - 灵活的数据结构
与提供有限数据结构的简单键值数据存储不同,Redis 可提供各种各样的数据结构,以满足您的应用程序需求。Redis 数据类型包括:
字符串 – 最大 512MB 的文本或二进制数据
列表 – 按添加顺序列出的字符串集合
集 – 未排序的字符串集合,支持与其他集类型的相交、联合以及差运算
排序集 – 根据值排序的集
哈希 – 同于存储字段和值的列表
地理空间 – 用于标记存储位置坐标
位图 – 提供位级操作
3 - 简单性和易用性
借助 Redis,您可以减少用于存储、访问和使用应用程序中的数据的代码行数,从而简化您的代码。例如,如果您的应用程序将数据存储在 HashMap 中,而您想将这些数据存储在数据存储中,那么只需使用 Redis 哈希数据结构来存储这些数据即可。至于没有哈希数据结构的数据存储中的相似任务,则需要许多行代码才能从一种格式转换为另一种格式。Redis 附带有原生数据结构和许多选项,以操作您的数据并与之交互。Redis 开发人员可以使用一百多种开源客户端。支持的语言包括 Java、Python、PHP、C、C++、C#、JavaScript、Node.js、Ruby、R、Go 等。
4 - 复制和持久性
Redis 采用的是主副本架构,并支持异步复制,用户执行此类复制时可以将数据复制到多个副本服务器。它能够提供更出色的读取性能(因为请求可以在多个服务器间进行拆分)和恢复功能(主服务器发生中断时)。为了实现持久性,Redis 支持时间点备份(将 Redis 数据集复制到磁盘)。
5 - 高可用性和可扩展性
Redis 在单个主节点或群集拓扑中提供主副本架构。这让您可以构建高度可用的解决方案,从而提供一致的性能和可靠性。如果您需要调整群集大小,它还为您提供了多种选项,包括横向扩展、纵向缩减或扩展。这让您的群集能够根据您的需求而发展。
6 - 可延展性
Redis 是一个开源项目,由充满活力的社区提供支持。Redis 是基于开放标准的,没有任何供应商或技术限制。它支持开放的数据格式,并拥有大量客户。
写在最后
有上面8条使用场景,我觉得,成熟的设计方案,不需要我们重新造轮子了吧。
网友四:
非常有兴趣回答这个问题。
Redis是目前最为流行的分布式缓存的解决方案,其凭借其出色的性能深受大家的欢迎。虽然Redis自身也提供了发布/订阅相应的功能,不过相对缓存来说,受欢迎程度就不那么高了。接下来,我来回答题主问题,说明样的数据适合放入Redis中(可以延伸到:何种类型的数据适合进行缓存处理)。

一、静态数据
最常见的就是各种参数、字典,这类数据往往在维护后数据量就恒定了,而且在系统运行过程中基本都是查询类型的操作。
在缓存算法方面,因为其数据量比较固定,而且不需要有过期的设定,所以这类数据不需要对其缓存算法(FIFO/LFU/LRU)有过多的要求,存下来就可以了。
在缓存策略方面,通常会选择Cache-Aside作为这类数据的缓存策略,应用有限读取缓存中的数据,如果数据不存在则从数据库中进行读取,读取后同步到缓存当中(在应用程序中通常会通过面向切面的方式来实现)。但是Cache-Aside并不能确保缓存和数据库的一致性(AB线程在查询数据库时数据发生了改变,导致A线程拿到的是a数据,B线程拿到的是b数据,那么很难保证AB线程最后put到缓存中的数据是最后更新的数据)。此外,通常会在应用启动时或提供人工操作的功能进行缓存预热,来防止缓存穿透。
二、临时数据
这一类数据最大的特点是时效性很强,并且不需要进行持久化。我们常见的Session、Token、以及各种验证码等。
在缓存算法方面,没有过多要求(缓存算法基本都是在空间恒定的情况下并且有优先顺序才会讨论的),但是需要考虑Redis分配内存的大小,必要时可以考虑持久化或者限流。
这类数据往往是由应用程序直接对缓存进行操作的。
三、热点数据
缓存热点数据的特征是并发查询非常多,例如商品信息,这类数据是动态变化的。
在缓存算法方面,通常会使用LFU/LRU或一些相关算法作为缓存算法,除了算法本身需要斟酌外,热点数据的定义也是一个非常值得研究的问题。
在缓存策略方面,或许Read-Through是个不错的选择。此外,还需要结合具体情况来制定相应防止缓存异常(穿透、击穿、雪崩)的策略,常见的有缓存预热、分级缓存、限流等等。
以上就是我的一个看法,关于算法和策略的选择上需要结合实际情况进行,但是缓存本身的意义是不变的:
1、减轻数据库压力(读写分离可以分担一些读的压力,但是还是远远不够);
2、临时性存储。
基于此,评估数据是否进行缓存的核心思想以及重要指标就是:在场景中对数据的查询操作对数据库的影响程度。
网友五:
如果项目中业务需求对数据库进行高并发的读写、海量数据高效的访问以及存储、对数据库有着较高的扩展性、高可用性要求都可以优先考虑使用Redis。

目前Redis凭借其优秀的读写性能、支持数据的持久化、丰富的数据类型、诸多便利的特性以及服务器端的良好扩展并易于运维,在NoSql阵营中脱颖而出,成为了一颗闪耀之星!深受开发人员以及企业的青睐,已经成为后台开发人员武器库中必不可缺的技术之一。

接下来结合其特性谈谈Redis适用的业务场景有哪些:
数据缓存:
这是NoSql技术相对传统的关系型数据库来说最具备优势的一个领域,对于一些读取非常频繁的数据完全可以放到Redis提供给系统功能访问。例如:token信息、用户身份信息(唯一性验证)、高频缓存数据(坐标、位置、地理信息)、短信验证码、搜索关键字、订单信息等都可以使用Redis进行存储。

统计:
在项目中我们经常会遇到一些需要记录与统计某项的数据,此类数据一般都非常庞大,如果存放在数据库中可以满足我们的需求,但是得不偿失、非常不划算!例如:文章阅读统计、排行榜、网站计数器、投票、作品点赞量等等。

记录关系:
目前非常流行的短视频平台,例如抖音、快手等用户关注、被关注、相同关注等均可以使用Redis来进行存储简单而明了,避免了数据库中数据的冗余与访问、存储压力!

总结一下:
无论是关系型数据库,还是Nosql数据库都有着各自的优势以及适用的场景,在项目中要合理的设计、分配它们所扮演的角色,通过它们之间的紧密合作在项目中发挥其最大的优势!

网友六:
1:字典,配置类型的数据,因为更新频率很低,如果这类型数据调用量比较大的话,适合放到redis
2:热点数据,就是每天调用量很大的数据,而且更新频率不是很大,适合放到redis
3:虽然有些业务数据,每日调用量比较大,但是查询和处理逻辑复杂,这类数据不适合放到redis
4:基础数据量比较大,有多个维度的查询,不适合放到redis
5:对调用数据不确定使用频率怎样的,不适合放到redis
网友七:
很高兴能够看到和回答这个问题!
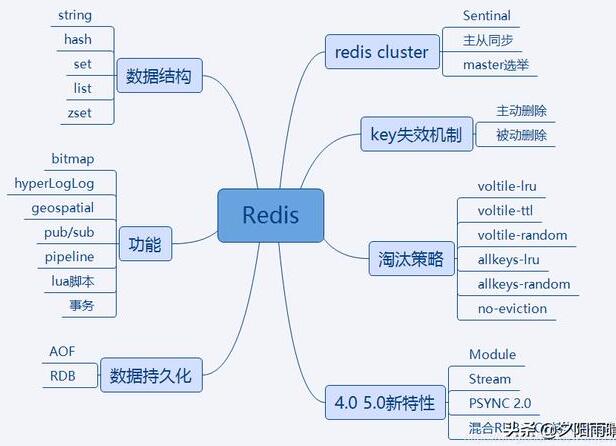
Redis是一个开放源代码(BSD许可)的内存中数据结构存储,用作数据库,缓存和消息代理。
它支持数据结构,例如字符串,哈希,列表,集合,带范围查询的排序集合,位图,超日志,带有半径查询和流的地理空间索引。 Redis具有内置的复制,Lua脚本,LRU驱逐,事务和不同级别的磁盘持久性,并通过Redis Sentinel和Redis Cluster自动分区提供高可用性。

Redis作为一个内存数据库,Redis具有很高的特性,QPS的例子可能是10 W,但是使用Redis通常会导致访问延迟。如果你不知道Redis执行了一个原则,那么在取样过程中就会出现混乱。那如何评估数据适不适合放入Redis中?
如果您经常使用更复杂的命令,例如,或者使用更多数据的命令,那么Redis数据处理过程将会更长。
如果维护请求的数量很小,但是Redis处理器的使用率很高,这可能是由于使用复杂命令造成的。
解决办法是尽可能避免使用这些更复杂的命令,并确保每个数据接收都不要太大,不能及时处理。
应该指出的是,当我们在互联网上扫描一把大钥匙时,QPS Redis将大幅增长。为了减少扫描过程对Redis的影响,我们必须使用控制参数来控制扫描频率,使每个扫描之间的间隔为一秒钟。
为了获得出色的性能,Redis使用内存中的数据集。根据您的用例,您可以通过将数据集偶尔转储到磁盘上,或者通过将每个命令附加到日志中来持久化它。如果只需要功能丰富的网络内存缓存,则可以选择禁用持久性。
缓存规则通常用于缓存。有限的缓存。没有缓存,访问数据将受到限制。
如果没有缓存,访问数据库将同步。然而,缓存的功能并不能提供缓存和数据库的顺序(AB行的变化导致了数据库请求A的讨论,但是B - B的讨论阻碍了数据缓存的最新更新。)此外,通常在应用程序启动或手动启动时,程序可以创建缓存,防止缓存进入。
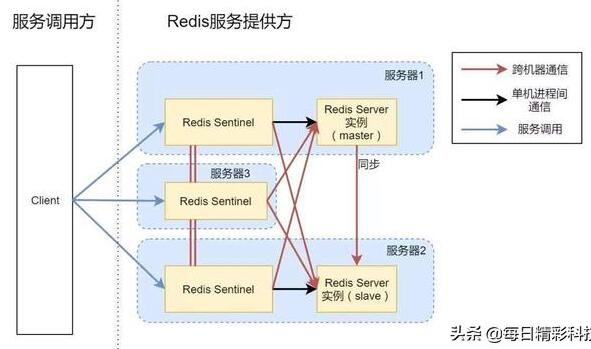
使用该命令的原则是Redis命令的内部执行,检查所有键,然后输入不同类型的键、控制和容器类型的元素数(列表/ dict / set / zset)。
初步数据的最大特征是,它们是非常临时的,不需要持续改进。我们经常遇到Session, Token和其他控制代码。
对于缓存算法来说,没有必要(缓存算法主要在空间分布和优先事项上讨论),但必须考虑到Redis内存的大小,并在必要时考虑到它们的稳定性或流量限制。对于容器中使用的键类型,只扫描最大元素的键,但是最大键不需要更多的内存。这需要我们的注意。然而,使用这个命令,我们通常可以更清楚地看到钥匙的位置。
由于严重的问题,Redis的钥匙在第4版中正式启动。0被用于异步释放大键的内存,以减少对Redis属性的影响。然而,我们不建议在移动集群时使用大键。大键也会影响机动性,这在集群的后续文章中详细说明了这一点。Redis还支持琐碎的设置主从异步复制,具有非常快速的非阻塞式第一次同步,自动重新连接以及网络拆分中的部分重新同步。
以上便是我的一些见解和回答,可能不能如您所愿,但我真心希望能够对您有所帮助!不清楚的地方您还可以关注我的头条号“每日精彩科技”我将竭尽所知帮助您!
Tags: 如何评估数据适不适合放入Redis中
分享到:

- 上一篇:论时装摄影模特的职业素养?
- 下一篇:最后一页
推荐文章
热门文章
最新评论文章
- 写给考虑创业的年轻程序员(10)
- PHP新手上路(一)(7)
- 惹恼程序员的十件事(5)
- PHP邮件发送例子,已测试成功(5)
- 致初学者:PHP比ASP优秀的七个理由(4)
- PHP会被淘汰吗?(4)
- PHP新手上路(四)(4)
- 如何去学习PHP?(2)
- 简单入门级php分页代码(2)
- php中邮箱email 电话等格式的验证(2)